The Best Server CPUs Compared, Part 1
by Johan De Gelas on December 22, 2008 10:00 PM EST- Posted in
- IT Computing
Virtualization (ESX 3.5 Update 2/3)
As we discussed in the first page of this article, virtualization will be implemented on about half of the servers bought this year. Virtualization is thus the killer application and the most important benchmark available. Since we have not been able to carry out our own virtualization benchmarking (due to the BIOS issues described earlier), we turn to VMware's VMmark. It is a relatively reliable benchmark as the number of "exotic tricks hardly used in the real world" (see SPECjbb) are very limited.
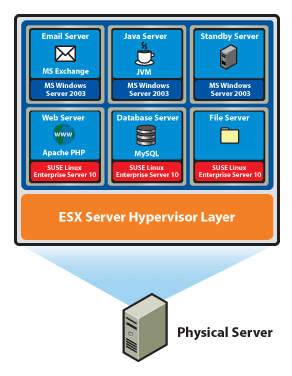
VMware VMmark is a benchmark of consolidation. Several virtual machines performing different tasks are consolidated together and called a tile. A VMmark tile consists of:
- MS Exchange VM
- Java App VM
- An Idle VM
- Apache web server VM
- MySQL database VM
- A SAMBA fileserver VM
The first three run on a Windows 2003 guest OS, the last three on SUSE SLES 10.
To understand why this benchmark is so important just look at the number of tiles that a certain machine can support:
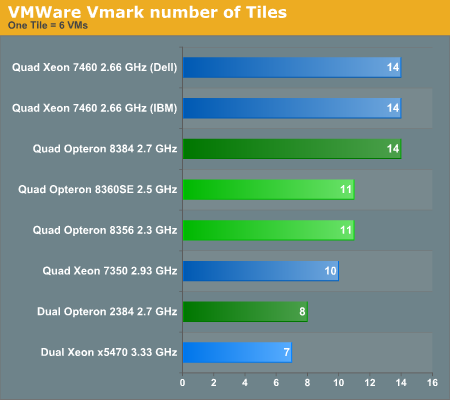
The difference between the Opteron 8360 SE and the 8384 "Shanghai" is only 200MHz and 4MB L3 cache. However, this small difference allows you to run 18 (!) extra virtual machines. Granted, it may require that you install more memory, but adding memory is cheaper than buying a server with more CPU sockets or adding yet another server. Roughly calculated you could say that the new quad-core Opteron allows you to consolidate 27% more virtual servers on one physical machine, which is a significant cost saving.
Of course, the number of tiles that a physical server can accommodate provides only a coarse-grain performance measure, but an important one. This is one of the few times where a higher benchmark score directly translates to a cost reduction. Performance per VM is of course also very interesting. VMware explains how they translate the performance of each different workload in different tiles into one overall score:
After a benchmark run, the workload metrics for each tile are computed and aggregated into a score for that tile. This aggregation is performed by first normalizing the different performance metrics such as MB/second and database commits/second with respect to a reference system. Then, a geometric mean of the normalized scores is computed as the final score for the tile. The resulting per-tile scores are then summed to create the final metric.
Let us take a look:
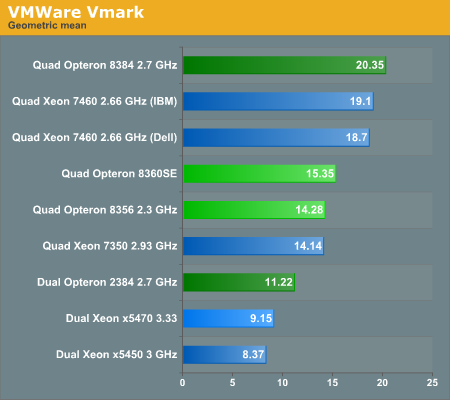
Thanks to the lower world switch times, higher clock speed, and larger cache, the new "Shanghai" Opteron 8384 improves the already impressive scores of the AMD "Barcelona" 8356 by almost 43%. The only Intel that comes somewhat close is the hex-core behemoth known as the Xeon X7460, which needs a lot more power. IBM is capable of performing a tiny bit better than Dell thanks to its custom high performance chipset.
It is clear that the Xeon 7350 is at the end of its life: it offers a little more than 2/3 of the performance of the best Opteron while using a lot more power. Even the latest improved stepping, the Xeon X5470 at 3.33GHz, cannot keep up with the new Opteron quad-core. The reason is simple: as the number of VMs increase, so do the bandwidth requirements and the amount of world switches. That is exactly where the Opteron is far superior. It is game over here for Intel… until the Xeon 5570 2.93GHz arrives in March.








29 Comments
View All Comments
Theunis - Wednesday, December 31, 2008 - link
I'm not entirely happy with the results, but I would also like to know the -march that was used to compile the 64bit Linux kernel and MySQL, and any other Linux benchmarks, because optimization for specific -march is crucial to compare apples with apples. Ok yes AMD wins by assuming standard/generic compile flags was used. But what if both were to use optimized architecture compile flags? Then if AMD lose they could blame gcc. But it still should be interesting to see the outcome of open source support. And how it wraps around Vendor support to open source and also the distribution that decided to go so far to support architecture specific (Gentoo Linux Distribution comes to mind).Intel knew that they were lagging behind because of their arch was too specific and wasn't running as efficiently on generic compiled code. Core i7 was suppose to fix this, But what if this is still not the case and optimization is required for architecture is still necessary to see any improvements on Intel's side?
James5mith - Tuesday, December 30, 2008 - link
Just wanted to mention that I love that case. The Supermicro 846 series is what I'm looking towards to do some serious disk density for a new storage server. I'm just wondering how much the SAS backplane affects access latencies, etc. (If you are using the one with the LSI expander chip.)Krobaruk - Saturday, December 27, 2008 - link
Just wanted to add a few bits of info. Back to an earlier comment, it is definitely incorrect to call SAS and infiniband the same, the cables are infact slightly different composition (Differences in shieliding) although they are terminated the same. Lets not forget that 10G ethernet uses the same termination in some implementations too.Also at least under Xen AMD platforms still do not offer PCI pass through, this is a fairly big inconvenience and should probably be mentioned as support is not expected until the HT3 Shanghais release later this year. Paricularly interesting are result here that show despite NUMA greatly reducing load on the HTLinks, it makes very little difference to the VMMark result:
http://blogs.vmware.com/performance/2007/02/studyi...">http://blogs.vmware.com/performance/2007/02/studyi...
I would imagine HT3 Opteron will only really benefit 8way opterons in typical figure of 8 config as the bus is that much heavier loaded.
Its odd your Supermicro quad had problems with the Shanghais and certain apps, no problems from testing with a Tyan TN68 here. Was the bios beta?
Are any benches with Xen likely to happen in future or is Anandtech solidly VMWare?
Answering another users questions about mailserver and spam assasin, I do not know of any decent bechmarks for this but have seen the load that different mailfilter servers can handle under the MailWatch/Mailgate system. Fast SAS raid 1 and dual quad cores seems to give best value and ram requirement is about 1Gb per core. Would be interesting to see some sort of linux mail filter benchmarks if you can construct something to do this.
RagingDragon - Saturday, December 27, 2008 - link
I'd imagine alot of software development servers are used for testing of applications which fall into one of the other categories. There'd also be bug tracking and version control servers, but most interesting from a performance perspective might be build servers (i.e. servers used for compiling software) - the best benchmark for that would probably be compile times for various compilers (i.e. Gnu, Intel and MS C/C++ compilers; Sun, Oracle and IBM java compilers; etc.)bobbozzo - Friday, December 26, 2008 - link
IMO, many (most?) mailservers need more than fast I/O; what with so much anti-spam and anti-virus filtering going on nowadays.SpamAssassin, although wonderful, can be slow under heavy loads and with many features enabled, and the same goes for A/Vs such as clamscan.
That said, I don't know of any good benchmarks.
vtechk - Thursday, December 25, 2008 - link
Very nice article, just the Fluent benchmarks are far too simple to give relevant information. Standard Fluent job these days has 25+ million elements, so sedan_4m is more of a synthetic test than a real world one. It would also be very interesting to see Nastran, Abaqus and PamCrash numbers.Amiga500 - Sunday, December 28, 2008 - link
Just to reinforce Alpha's comments... 25 million being standard isn't even close to being true!!!Sure, if you want to perform a full global simulation, you'll need that number (and more) for something like a car (you can add another 0 to the 25 million for F1 teams!), or an aircraft.
But, mostly, the problems are broken down into much smaller numbers, under 10 million cells. A rule of thumb with fluent is 700K cells for every GB of RAM... so working on that principal, you'd need a 16GB workstation for 10 million cells...
Anything more, and you'll need a full cluster to make the turnaround times practical. :-)
alpha754293 - Saturday, December 27, 2008 - link
"Standard Fluent job these days has 25+ million elements"That's NOT entirely true. The size of the simulation is dependent on what you are simulating. (And also hardware availability/limitations).
Besides, I don't think that Johan actually ran the benchmarks himself. He just dug up the results database and mentioned it here (wherever the processor specs were relevant).
He also makes a note that the benchmark itself can be quite costly (e.g. a license of Fluent can easily be $20k+), and there needs to be a degree of understanding to be able to run the benchmark itself (which he also stated that neither he, nor the lab has.)
And on that note - Johan, if you need help in interpreting the HPC results, feel free to get in touch with me. I sent you an email on this topic (I'm actually running the LS-DYNA 3-car collision benchmark right now as we speak on my systems). I couldn't find the case data to be able to run the Fluent benchmarks as well, but IF I do; I'll run it and I'll let you know.
Otherwise, EXCELLENT. Looking forward to lots more coming from you once the NDA is lifted on the Nehalem Xeons.
zpdixon42 - Wednesday, December 24, 2008 - link
Johan,The article makes a point of explaining how fair the Opteron Killer? section is, by assuming that unbuffered DDR3-1066 will provide results close enough to registered DDR3-1333 for Nehalem. But what is nowhere mentioned is that all of the benchmarks unfairly penalize the 45nm Opteron because registered DDR2-800 was used whereas faster DDR2-1067 is supported by Shanghai. If you go into great length justifying memory specs for Intel, IMHO you should mention that point for AMD as well.
The Oracle Charbench graph shows "Xeon 5430 3.33GHz". This is wrong, it's the X5470 that runs at 3.33GHz, the E5430 runs at 2.66GHz.
The 3DSMax 2008 32 bit graph should show the Quad Opteron 8356 bar in green color, not blue.
In the 3DSMax 2008 32 bit benchmark, some results are clearly abnormal. For example a Quad Xeon X7460 2.66GHz is beaten by an older microarchitecture running at a slower speed (Quad Xeon 7330 2.4GHz). Why is that ?
The article mentions in 2 places the Opteron "8484", this should be "8384".
The Opteron Killer? section says "the boost from Hyper-Threading ranges from nothing to about 12%". It should rather say "ranges from -5% to 12%" (ie. HT degrades performance in some cases).
There is a typo in the same section: "...a small advantage at* it can use..." s/at/as/.
Also, I think CPU benchmarking articles should draw graphs to represent performance/dollar or performance/watt (instead of absolute performance), since that's what matters in the end.
JohanAnandtech - Wednesday, December 24, 2008 - link
"But what is nowhere mentioned is that all of the benchmarks unfairly penalize the 45nm Opteron because registered DDR2-800 was used whereas faster DDR2-1067 is supported by Shanghai. "Considering that Shanghai has just made DDR-2 800 (buffered) possible, I think it is highly unlikely that we'll see buffered DDR-2 1066 very soon. Is it possible that you are thinking of Deneb which can use DDR-2 1066 unbuffered?
"In the 3DSMax 2008 32 bit benchmark, some results are clearly abnormal. For example a Quad Xeon X7460 2.66GHz is beaten by an older microarchitecture running at a slower speed (Quad Xeon 7330 2.4GHz). Why is that ? "
Because 3DS Max does not like 24 cores. See here:
http://it.anandtech.com/cpuchipsets/intel/showdoc....">http://it.anandtech.com/cpuchipsets/intel/showdoc....
"Also, I think CPU benchmarking articles should draw graphs to represent performance/dollar or performance/watt (instead of absolute performance), since that's what matters in the end. "
In most cases performance/dollar is a confusing metric for server CPUs, as it greatly depends on what application you will be running. For example, if you are spending 2/3 of your money on a storage system for your OLTP app, the server CPU price is less important. It is better to compare to similar servers.
Performance/Watt was impossible as our Quad Socket board had a beta BIOS which disabled powernow! That would not have been fair.
I'll check out the typos you have discovered and fix them. Thx.